16 minutes
How MCP Changes the Way We Write Software
- Agents: The Current Reality
- Where Generative AI Excels Today: The Case for Coding
- The Model Context Protocol
- Programming in the Era of LLMs
- Conclusion
Agents: The Current Reality
When we talk about “agents” in the context of AI today, it’s important to clarify what we mean, especially from a reinforcement learning (RL) perspective. Strictly speaking, most current AI systems referred to as agents don’t yet fit the classical RL definition.
In reinforcement learning, an agent learns a “policy” π(s) – a strategy for choosing actions – by interacting with an “environment” over time, receiving feedback (rewards or penalties). This policy is learned through trial and error, adapting based on experience to maximize cumulative reward.
Many systems labeled as “agents” today, however, operate through static, human-authored prompts that serve as fixed behavioral specifications rather than learned policies. While these prompts can be dynamic and involve multiple steps or tool use, the core “policy” guiding behavior is nevertheless hardcoded. So what the industry refers to as “agents” can be more accurately described as interfaces that leverage natural language or pseudocode-like instructions to interact with underlying software functionalities.
Where Generative AI Excels Today: The Case for Coding
Despite the limitations in achieving true agency, large language models still demonstrate considerable utility in the context of software development. This effectiveness stems from two domain-specific characteristics that align well with current model capabilities:
- Tolerance for Error and Iteration: Generated code doesn’t need to be perfect on the first try. Unlike real-time systems(which the industry seems to be using “agents” for), coding allows for an iterative process. Developers can review, debug, and refine AI-generated suggestions.
- Objective Verification: In software engineering, we have mechanisms to verify the correctness of code, primarily through automated tests. Instead of accepting AI output at face value (as one might with a factual query), we can run unit tests, integration tests, linters, etc to objectively determine if the generated code functions as intended.
In other words, one can view programming as fundamentally analogous to a reinforcement learning problem, where the generated code serves as the agent’s policy, and tests provide feedback on the various states the agent can be in.
With all of that in mind, I would like to spend the rest of this blog post describing how MCP servers can augment the way developers write code with LLMs, and exploring which features of programming languages are best suited for this new AI-assisted development paradigm.
The Model Context Protocol
At its core, the Model Context Protocol(well at least the “tool” part of the protocol) is surprisingly simple. For a server to adhere to the MCP standard, it primarily needs to implement just two methods:
list_tools: This method allows a client to discover the available functions or capabilities the server offers.call_tool: This method allows the client to execute one of the discovered tools, providing necessary parameters.
Late Binding: Decoupling Clients from Service Details
Unlike traditional architectures, where clients are tightly coupled to specific, predefined API endpoints, an MCP client interacts with a single, generic MCP endpoint provided by a service or service wrapper. The precise function or “tool” to be invoked, along with its required parameters, isn’t hardcoded into the client. Instead, this determination happens dynamically at runtime. The client’s intent, often expressed in natural language, is processed by an intermediary (like an LLM) which consults the service’s capabilities (discovered via a list_tools mechanism) to decide the correct tool and parameters to use.
Furthermore, because clients discover and bind to tools dynamically at runtime, server implementations gain greater flexibility to evolve. As long as the updated server correctly describes its current capabilities via the list_tools mechanism, clients can adapt to changes in functionality, parameter lists, or even underlying implementation details without requiring synchronized code deployments or potentially breaking existing client code. This significantly reduces the coordination overhead and risk typically associated with rolling out API changes.
LLMs Calling Functions: Rethinking Interaction
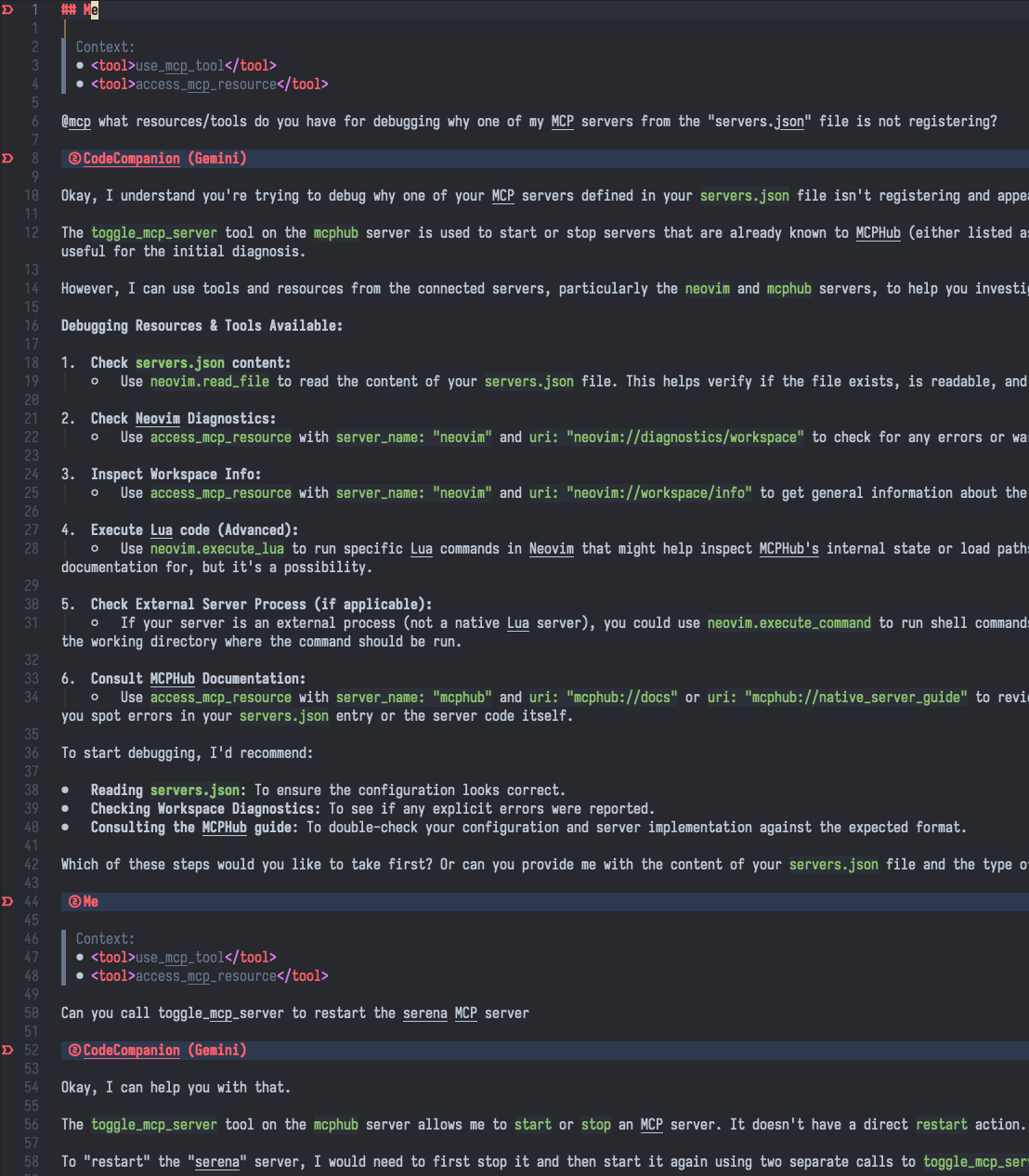
In the picture above, we see that I simply just “asked” the LLM to restart a certain MCP server. Under the hood, it is making an HTTP request. For programmers, a significant part of their job often involves not writing new code, but figuring out which existing API to call to achieve a desired outcome. Instead of manually searching documentation, understanding complex request formats, hoping you don’t make a typo in a JSON request, etc, the LLM handles this complexity. Because of that, it opens the door to having conversations with software. Instead of using complex command-line tools or web interfaces, a user could simply say, “Restart the database server for the production environment,” or “Scale up the web server cluster by two instances,” or “Deploy the latest version of the user authentication service”.
And this benefit is not just limited to programmer-server interaction. If applications themselves expose their capabilities via an MCP server, ordinary users can “talk” to them directly through an intelligent agent interface. Users will no longer need to search through menus or remember complex command sequences. Furthermore This opens the door to “dynamic” user interfaces. Instead of UI elements being hardcoded into the application, an LLM could interpret the user’s request (e.g., “show me a graph of my spending last month”) and use MCP to query the application’s capabilities. It could then select the necessary UI components (a date picker tool, a charting tool, a data retrieval tool) and send them along with the relevant data or instructions to a “window manager” or rendering engine for display and interaction. In essence, the sci-fi interfaces you see in movies – complex, fluid, and language aware, are now possible with MCP!
Programming in the Era of LLMs
The advent of Large Language Models (LLMs) has fundamentally altered the programming landscape. As AI assistants become increasingly capable of generating code at unprecedented speed and scale, we must reconsider what makes a programming language ideal—not just for human developers, but for AI-human collaborative development. In particular, a LLM friendly programming language should:
- Minimizes bugs. AI should be able to implement the user’s intent without racking up a bunch of bugs along the way.
- A language with a standarized testing framework and good compile messages. The more verification we can introduce in the LLM code generation cycle, the more we are willing to vibe code.
- One which encourages developers to have verbose, pendantic descriptions of their code, perhaps even providing examples of how the API can be used.
And with all that said, it seems we do have such a programming language already. And that programming language is Rust. Let me explain
Making Unrepresentable States Unreachable
While Rust’s type system includes features like Variants (Algebraic Data Types) for ensuring type safety, I want to focus on a less commonly discussed concept: Phantom Types. Phantom types allow you to embed business logic directly within the type definitions themselves, achieving a state where invalid business states simply cannot be represented or constructed by the compiler.
use std::marker::PhantomData;
// State machine for user account verification
#[derive(Debug)]
pub struct Unverified;
#[derive(Debug)]
pub struct EmailVerified;
#[derive(Debug)]
pub struct FullyVerified;
#[derive(Debug)]
pub struct UserAccount<State> {
email: String,
username: String,
created_at: chrono::DateTime<chrono::Utc>,
_state: PhantomData<State>,
}
impl UserAccount<Unverified> {
pub fn new(email: String, username: String) -> Self {
Self {
email,
username,
created_at: chrono::Utc::now(),
_state: PhantomData,
}
}
// Can only verify email from unverified state
pub fn verify_email(self, verification_code: &str) -> Result<UserAccount<EmailVerified>, VerificationError> {
if self.is_valid_verification_code(verification_code) {
Ok(UserAccount {
email: self.email,
username: self.username,
created_at: self.created_at,
_state: PhantomData,
})
} else {
Err(VerificationError::InvalidCode)
}
}
fn is_valid_verification_code(&self, _code: &str) -> bool {
// Simulate verification logic
true
}
}
impl UserAccount<EmailVerified> {
// Can only complete verification after email is verified
pub fn complete_verification(self, phone_number: String) -> Result<UserAccount<FullyVerified>, VerificationError> {
if self.is_valid_phone(phone_number.as_str()) {
Ok(UserAccount {
email: self.email,
username: self.username,
created_at: self.created_at,
_state: PhantomData,
})
} else {
Err(VerificationError::InvalidPhone)
}
}
fn is_valid_phone(&self, _phone: &str) -> bool {
// Simulate phone validation
true
}
}
impl UserAccount<FullyVerified> {
// Only fully verified users can make purchases
pub fn make_purchase(&self, amount: u64) -> Result<PurchaseReceipt, PaymentError> {
if amount > 0 {
Ok(PurchaseReceipt {
user_email: self.email.clone(),
amount,
timestamp: chrono::Utc::now(),
})
} else {
Err(PaymentError::InvalidAmount)
}
}
// Only fully verified users can access sensitive data
pub fn get_personal_data(&self) -> PersonalData {
PersonalData {
email: self.email.clone(),
username: self.username.clone(),
verified_at: self.created_at,
}
}
}
#[derive(Debug)]
pub enum VerificationError {
InvalidCode,
InvalidPhone,
}
#[derive(Debug)]
pub enum PaymentError {
InvalidAmount,
InsufficientFunds,
}
#[derive(Debug)]
pub struct PurchaseReceipt {
user_email: String,
amount: u64,
timestamp: chrono::DateTime<chrono::Utc>,
}
#[derive(Debug)]
pub struct PersonalData {
email: String,
username: String,
verified_at: chrono::DateTime<chrono::Utc>,
}
// Usage example - invalid transitions are compile-time errors
fn demonstrate_type_safety() {
let unverified_user = UserAccount::new(
"user@example.com".to_string(),
"username".to_string()
);
// This compiles - valid transition
let email_verified = unverified_user.verify_email("123456").unwrap();
// This compiles - valid transition
let fully_verified = email_verified.complete_verification("+1234567890".to_string()).unwrap();
// This compiles - only fully verified users can make purchases
let receipt = fully_verified.make_purchase(100).unwrap();
// These would be COMPILE-TIME ERRORS:
// let unverified_user = UserAccount::new("email".to_string(), "user".to_string());
// unverified_user.make_purchase(100); // ERROR: method doesn't exist for UserAccount<Unverified>
// unverified_user.get_personal_data(); // ERROR: method doesn't exist for UserAccount<Unverified>
// let email_verified = unverified_user.verify_email("123456").unwrap();
// email_verified.verify_email("456789"); // ERROR: method doesn't exist for UserAccount<EmailVerified>
}
This approach, using phantom types to represent distinct business states like Unverified or FullyVerified, provides powerful guidance for LLMs. The type system explicitly encodes the valid state transitions by making specific methods (like verify_email or make_purchase) available only on the correct state types. This acts as a detailed map for the LLM, teaching it the precise sequence of operations and underlying business rules required. Crucially, the compiler then enforces these rules, making it impossible for the LLM to generate code that attempts invalid actions, such as allowing a user in the Unverified state to perform a purchase. This strong, compile-time guidance prevents a class of logical bugs related to incorrect state management, ensuring the generated code adheres strictly to the defined business flow.
Visible Error Handling: unwrap() as LLM Guidance
Rust’s approach to error handling, particularly through visible indicators like unwrap(), provides LLMs with clear signals about potential failure points, guiding them toward generating more robust and correct code.
use std::fs::File;
use std::io::Read;
fn process_user_config(file_path: &str) -> String {
let mut file = File::open(file_path).unwrap(); // <- LLM sees this needs error handling
let mut contents = String::new();
file.read_to_string(&mut contents).unwrap(); // <- Another unwrap - needs handling
let parsed_config = serde_json::from_str(&contents).unwrap(); // <- JSON parsing can fail
let username = parsed_config["username"].as_str().unwrap(); // <- Field might not exist
format!("Welcome, {}!", username)
}
Each .unwrap() call explicitly marks a location where a Result type, indicating potential failure, was handled by simply panicking on error. For an LLM processing this code, these are clear instructions: “At this exact point, an error could occur. Make sure to have a test case which covers this”
Compared with the Python version:
import json
import os
def process_user_config(file_path: str) -> str:
with open(file_path, 'r') as f:
contents = f.read()
parsed_config = json.loads(contents)
username = parsed_config['username']
return f"Welcome, {username}!"
In the Python code, the potential failure points are not marked by specific syntax at the call site itself. An LLM must rely more on its training data and context to infer where exceptions might be raised. This implicit nature makes it more challenging for the LLM to reliably identify and cover all necessary error handling cases compared to the explicit flagging provided by Rust’s unwrap(). While human developers might favor Python for its conciseness, Rust’s explicit syntax will be favored by LLMs to generate correct code.
The Power of Descriptive Compiler Messages
Rust’s compiler messages exemplify this principle. When an LLM generates incorrect Rust code, the compiler doesn’t just say “error”—it provides educational, contextual feedback:
struct User {
id: i32,
name: String,
}
fn main() {
let current_user = User {
id: 1,
name: String::from("Alice"),
};
let status = current_user.get_login_status(); // Compile error here
println!("Login status: {:?}", status);
}
Compiling this code yields the following error:
error[E0599]: no method named `get_login_status` found for struct `User` in the current scope
--> main.rs:12:31
|
1 | struct User {
| ----------- method `get_login_status` not found for this struct
...
12 | let status = current_user.get_login_status(); // Compile error here
| ^^^^^^^^^^^^^^^^ method not found in `User`
error: aborting due to 1 previous error
For more information about this error, try `rustc --explain E0599`.
The Rust error E0599 clearly states “no method named get_login_status found for struct User”. It precisely identifies the struct (User) and the method name being sought (get_login_status), along with the exact location in the code. And while this specific simple example doesn’t show suggestions, in more complex cases involving traits or common typos, Rust often suggests methods that are available or might be similar, providing more detailed insight into why the method wasn’t found on that specific type and helping the developer find the correct method or understand what traits are missing. And if that is not enough, the LLM can call rustc --explain E0599 for an example of how to solve the issue!
Compare this with the equivalent error in Go:
package main
import "fmt"
type User struct {
id int
name string
}
func main() {
currentUser := User{
id: 1,
name: "Alice",
}
status := currentUser.get_login_status() // Compile error here
fmt.Println("Login status:", status)
}
Compiling this code yields an error similar to this:
# command-line-arguments
./main.go:16:24: currentUser.get_login_status undefined (type User has no field or method get_login_status)
The Go error message is concise: “currentUser.get_login_status undefined (type User has no field or method get_login_status)”. It correctly identifies the variable (currentUser), the method being called (get_login_status), and states that it’s undefined on the User type, explicitly mentioning that the type has no such field or method. While accurate and to the point, it lacks the detailed breakdown, potential suggestions, or specific error code often found in Rust errors, making it slightly less descriptive in guiding the LLM towards resolving the issue.
Localized Testing
Rust’s support for embedded unit tests creates exceptional locality between implementation and verification code, making it uniquely well-suited for LLM-generated programs. Unlike many languages that require separate test files, Rust allows developers to write tests directly alongside their implementation using the #[cfg(test)] attribute and #[test] macro.
pub fn capitalize_words(input: &str) -> String {
input
.split_whitespace()
.map(|word| {
let mut chars = word.chars();
match chars.next() {
None => String::new(),
Some(first) => first.to_uppercase().collect::<String>() + chars.as_str(),
}
})
.collect::<Vec<_>>()
.join(" ")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_capitalize_basic() {
assert_eq!(capitalize_words("hello world"), "Hello World");
}
#[test]
fn test_capitalize_empty() {
assert_eq!(capitalize_words(""), "");
}
#[test]
fn test_capitalize_single_char() {
assert_eq!(capitalize_words("a b c"), "A B C");
}
}
This unified view provides immediate, high-quality context to the LLM. It can reason about the implementation and simultaneously see how it should behave according to the tests. In other programming languages, the LLM may need to retrieve corresponding tests from a separate location, potentially relying on external search mechanisms with a possibility of false positives(i.e RAG database). In Rust, however, this crucial verification context is inherently available alongside the implementation within the same file, ensuring the LLM always has immediate access to the tests that define expected behavior for unit-level code.
Documentation as Verified Executable Specification
/// Processes user authentication with multi-factor verification
///
/// # Arguments
/// * `credentials` - User credentials containing username/email and password
/// * `mfa_token` - Time-based one-time password from authenticator app
/// * `device_info` - Information about the requesting device for security logging
///
/// # Returns
/// * `Ok(AuthResult)` - Successful authentication with user session
/// * `Err(AuthError)` - Authentication failure with detailed reason
///
/// # Examples
/// ```
/// use auth::{Credentials, DeviceInfo, authenticate_user};
///
/// let creds = Credentials {
/// username: "user@example.com".to_string(),
/// password: "secure_password".to_string(),
/// };
///
/// let device = DeviceInfo {
/// user_agent: "Mozilla/5.0...".to_string(),
/// ip_address: "192.168.1.100".to_string(),
/// device_id: Some("known_device_123".to_string()),
/// };
///
/// match authenticate_user(creds, "123456", device) {
/// Ok(result) => println!("Authenticated: {}", result.user_id),
/// Err(e) => eprintln!("Auth failed: {:?}", e),
/// }
/// ```
///
/// # Security Notes
/// - Passwords are automatically hashed and never stored in plaintext
/// - Failed attempts are rate-limited per IP and per user
/// - MFA tokens are validated against time skew up to 30 seconds
/// - Device fingerprinting helps detect suspicious login patterns
///
/// # Performance
/// - Typical response time: 50-200ms
/// - Database queries: 2-3 (user lookup, session creation, audit log)
/// - Memory usage: ~1KB per authentication attempt
fn authenticate_user(
credentials: Credentials,
mfa_token: &str,
device_info: DeviceInfo,
) -> Result<AuthResult, AuthError> {
// Implementation here
}
In Rust, documentation is a first-class citizen that goes far beyond simple comments. Rust guarantees that the example code blocks embedded in documentation must compile without errors, or cargo build will fail. This means that Rust documentation must be correct! These documentation blocks are furthermore compiled into static HTML pages by rustdoc, which can subsequently become a valuable MCP (Model Context Protocol) resource for AI systems. The rich, structured documentation provides detailed behavioral specifications and usage patterns that help the LLM understand not just what the code does, but how it should be used in practice. This creates a virtuous cycle where well-documented generated code becomes the foundation for even better subsequent generations, as the LLM can learn from the comprehensive specifications it helped create.
Conclusion
While true agentic AI is not yet fully realized, the introduction of the Multi-Capability Protocol (MCP) represents a significant step forward. Despite the current limitations, MCP provides a crucial framework, bringing us closer to achieving sophisticated agents. At its core, MCP gives Large Language Models (LLMs) a structured way to interact with external environments. Now what is left to do from the reinforcement learning perspective is a way to assign “rewards” to the “actions” the LLM takes.(perhaps evals with Long Term Memory??). But until the day that AGI comes, a lot of software engineering needs to be done to build up AI infrastructure. Just off the top of my head, here are some ideas:
MCP Chat Debugger
MCP Chat Debugger represents a critical need in agent development. Current debugging approaches are inadequate for systems that make autonomous decisions and interact with external environments. An MCP Chat Debugger would allow developers to step into the “conversation” between the LLM and MCP servers, observing the agent’s reasoning process, the data it receives, and the decisions it makes. This tool would need to capture not just the final outputs, but the entire chain of reasoning, including failed attempts, backtracking, and learning updates.
Agent Monitoring and Observability Systems
These systems need to track metrics that don’t exist in traditional software: decision quality, learning velocity, goal achievement rates, and resource utilization efficiency. Unlike traditional monitoring, agent observability must account for the probabilistic nature of AI decision-making and the long-term consequences of actions. These monitoring systems will need to detect when agents are behaving unexpectedly, learning counterproductive patterns, or operating outside their intended parameters. They’ll need to provide alerts not just for system failures, but for subtle degradations in agent performance that might indicate training drift or environmental changes.
Agent Operating System
Agent Operating System represents perhaps the most ambitious requirement. Current operating systems are designed for deterministic programs following predictable execution patterns. Agents require an entirely different computational model—one that supports continuous learning and goal-oriented behavior. It would need to manage not just computational resources, but learning resources—tracking which experiences are worth retaining, managing memory consolidation as the context window grows too big(instead of stack overflow, we now have context overflow). This necessitates an operating system fundamentally built for dynamic, learning-driven computation rather than static, command-driven execution.
The race to build these foundational tools and infrastructure will determine not just who leads the next wave of AI development, but who shapes the very architecture of how humans and machines will collaborate in an agentic future.